题目描述:
记得一副有趣的对联: “雾锁山头山锁雾, 天连水尾水连天”, 上联和下联都是回文的.当然类似的还有: “上海自来水水来自海上, 山西悬空寺寺空悬西山”.
回文是什么意思? 就是把内容反过来读也是和原来一样的, 譬如 abccba, xyzyx, 这些都是回文的.然而我们更感兴趣的是在一个英文字符串 L 中, 怎么找出最长的回文子串.例如 L = “caayyhheehhbbbhhjhhyyaac”, 那么它最长的回文子串是 “hhbbbhh”.这个任务看似简单, 但是如果我告诉你 L 的长度可能会接近 10^4, 问题似乎就变麻烦了.不管怎么说, 加油吧骚年.
示例:
输入:L = “caayyhheehhbbbhhjhhyyaac”
输出:hhbbbhh
## 分析:
方法一:暴力匹配
根据回文子串的定义,枚举所有长度大于等于 2 的子串,依次判断它们是否是回文。在具体实现时,可以只针对大于“当前得到的最长回文子串长度”的子串进行“回文验证”。
参考代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
# 回文验证
def is_valid(strr):
temp = strr[::-1]
return temp == strr
def find_palindrome(s):
ans = ""
lens = len(s)
for i in range(lens):
for j in range(i+1, lens):
# 这就是避免对小于最长回文子串的子串进行回文验证
if j-i+1 < len(ans):
continue
if is_valid(s[i:j+1]):
if len(ans) < (j-i+1):
ans = s[i:j+1]
return ans
暴力解法时间复杂度高,但是思路清晰、编写简单,因为编写的正确性的可能性很大,可以使用暴力匹配算法检验我们编写的其它算法是否正确。
其时间复杂度为 O(n3)
方法二:中心扩散法
暴力法采用双指针两边夹,验证是否是回文子串,时间复杂度比较高,除了枚举字符串的左右边界以外,比较容易想到的是枚举可能出现的回文子串的“中心位置”,从“中心位置”尝试尽可能扩散出去,得到一个回文串。
因此,中心扩散法的思路是:遍历每一个索引,以这个索引为中心,利用“回文串”中心对称的特点,往两边扩散,看最多能扩散多远。
因为是枚举中心位置,其时间复杂度为O(n), 然后依次向两边扩散,其时间复杂度也为O(n), 因此总体的时间复杂度就为O(n^2)。
但是这样枚举的话,其中奇数串和偶数串是不一样的。
奇数串的中心是一个具体的字符。
偶数串的中心是两个字符中间的“间隙”。

如何去解决这两种不一样的情况呢?
使用重新安排索引的方式。定义 left, right 两个下标索引。 要注意边界的控制。left >= 0 并且 right <= lens-1
奇数时: right = left,
偶数时:right = left + 1。
示例代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
def check(s, left, right, lens):
while(left>=0 and right <= lens-1 and s[left]==s[right]):
left -= 1
right += 1
# 当退出来的时候, 两个位置的字符实际上已经是不一样的了。
return left+1, right-1
def find_palindrome(s):
ans = ""
lens = len(s)
for i in range(lens):
left_1, right_1 = check(s, i, i, lens)
left_2, right_2 = check(s, i, i+1, lens)
if right_2 - left_2 > right_1 - left_1:
right_1, left_1 = right_2, left_2
if len(ans) < right_1 - left_1 + 1:
ans = s[left_1: right_1+1]
return ans
对于现在的这个题目,目前这个时间复杂度为 O(n2) 的就已经可以通过了。然后我还看到了第三种办法。
方法三:Manacher 算法
Manacher 算法,被中国程序员戏称为“马拉车”算法。它专门用于解决“最长回文子串”问题,时间复杂度为o(n)。
Manacher 算法本质上还是中心扩散法,只不过它使用了类似 KMP 算法的技巧,充分挖掘了已经进行回文判定的子串的特点,在遍历的过程中,记录了已经遍历过的子串的信息,也是典型的以空间换时间思想的体现。
下面介绍 Manacher 算法的具体流程。
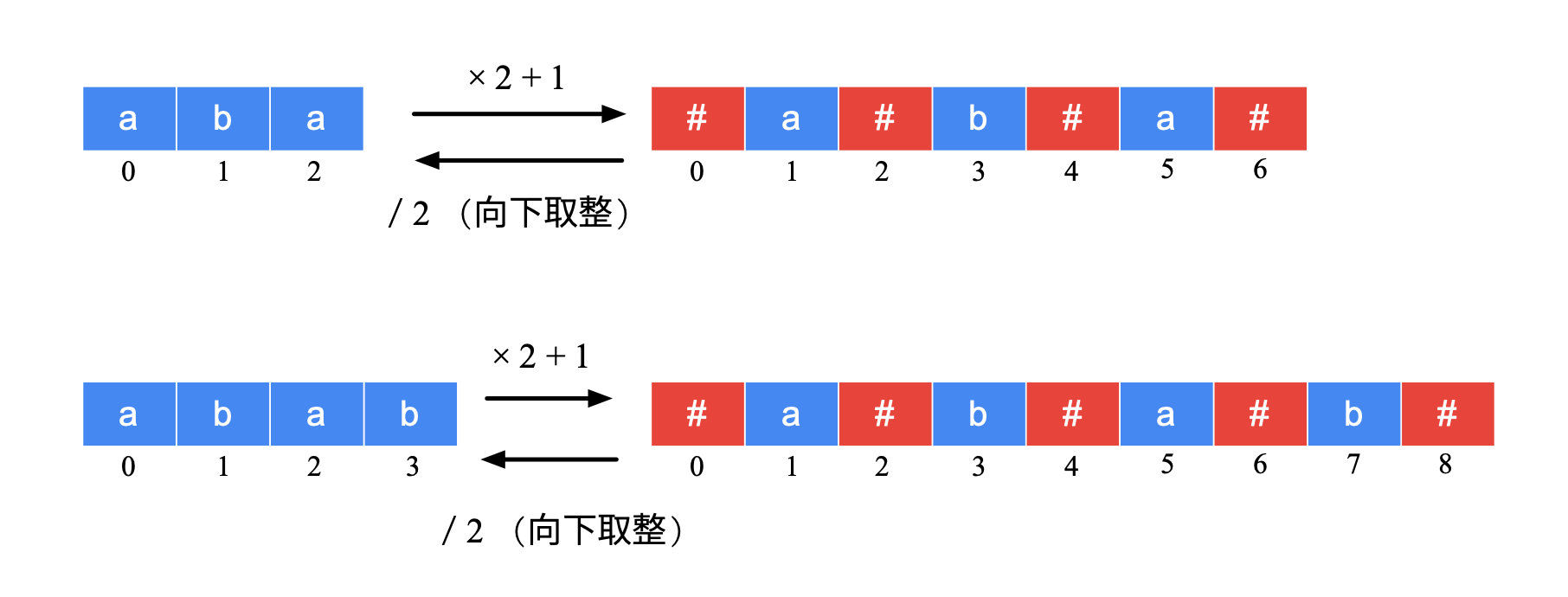
第 1 步:对原始字符串进行预处理(添加分隔符)
首先在字符串的首尾、相邻的字符中插入分隔符,例如 "babad" 添加分隔符 "#" 以后得到 "#b#a#b#a#d#"。
对这一点有如下说明:
1、分隔符是一个字符,种类也只有一个,并且这个字符一定不能是原始字符串中出现过的字符;
2、加入了分隔符以后,使得“间隙”有了具体的位置,方便后续的讨论,并且新字符串中的任意一个回文子串在原始字符串中的一定能找到唯一的一个回文子串与之对应,因此对新字符串的回文子串的研究就能得到原始字符串的回文子串;
3、新字符串的回文子串的长度一定是奇数;
4、新字符串的回文子串一定以分隔符作为两边的边界,因此分隔符起到“哨兵”的作用。
第 2 步:计算辅助数组 p
辅助数组 p 记录了新字符串中以每个字符为中心的回文子串的信息。
手动的计算方法仍然是“中心扩散法”,此时记录以当前字符为中心,向左右两边同时扩散,记录能够扩散的最大步数。
以字符串 "abbabb" 为例,说明如何手动计算得到辅助数组 p ,我们要填的就是下面这张表。
| char | # | a | # | b | # | b | # | a | # | b | # | b | # |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| index | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| p |
第 1 行数组 char :原始字符串加上分隔符以后的每个字符。
第 2 行数组 index :这个数组是新字符串的索引数组,它的值是从 0 开始的索引编号。
- 我们首先填
p[0]。
以 char[0] = '#' 为中心,同时向左边向右扩散,走 1 步就碰到边界了,因此能扩散的步数为 0, 因此 p[0] = 0;
| char | # | a | # | b | # | b | # | a | # | b | # | b | # |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| index | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| p | 0 |
- 下面填写
p[1]。
以 char[1] = 'a' 为中心,同时向左边向右扩散,走 1 步,左右都是 "#",构成回文子串,于是再继续同时向左边向右边扩散,左边就碰到边界了,最多能扩散的步数”为 1,因此 p[1] = 1;
| char | # | a | # | b | # | b | # | a | # | b | # | b | # |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| index | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| p | 0 | 1 |
- 下面填写
p[2]。
以 char[2] = '#' 为中心,同时向左边向右扩散,走 1 步,左边是 "a",右边是 "b",不匹配,最多能扩散的步数为 0,因此 p[2] = 0;
| char | # | a | # | b | # | b | # | a | # | b | # | b | # |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| index | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| p | 0 | 1 | 0 |
- 下面填写
p[3]。
以 char[3] = 'b' 为中心,同时向左边向右扩散,走 1 步,左右两边都是 “#”,构成回文子串,继续同时向左边向右扩散,左边是 "a",右边是 "b",不匹配,最多能扩散的步数为 1, 因此 p[3] = 1;
| char | # | a | # | b | # | b | # | a | # | b | # | b | # |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| index | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| p | 0 | 1 | 0 | 1 |
- 下面填写
p[4]。
以 char[4] = '#' 为中心,同时向左边向右扩散,最多可以走 4 步,左边到达左边界,因此 p[4] = 4。
| char | # | a | # | b | # | b | # | a | # | b | # | b | # |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| index | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| p | 0 | 1 | 0 | 1 | 4 |
- 继续填完 p 数组剩下的部分。
分析到这里,后面的数字不难填出,最后写成如下表格:
| char | # | a | # | b | # | b | # | a | # | b | # | b | # |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| index | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| p | 0 | 1 | 0 | 1 | 4 | 1 | 0 | 5 | 0 | 1 | 2 | 1 | 0 |
说明:有些资料将辅助数组 p 定义为回文半径数组,即 p[i] 记录了以新字符串第 i 个字符为中心的回文字符串的半径(包括第 i 个字符),与我们这里定义的辅助数组 p 有一个字符的偏差,本质上是一样的。
下面是辅助数组 p 的结论:辅助数组 p 的最大值是 5 ,对应了原字符串 "abbabb" 的 “最长回文子串” :"bbabb"。这个结论具有一般性,即:
“辅助数组
p的最大值就是“最长回文子串”的长度。”
因此,我们可以在计算辅助数组 p 的过程中记录这个最大值,并且记录最长回文子串。
简单说明一下这是为什么:
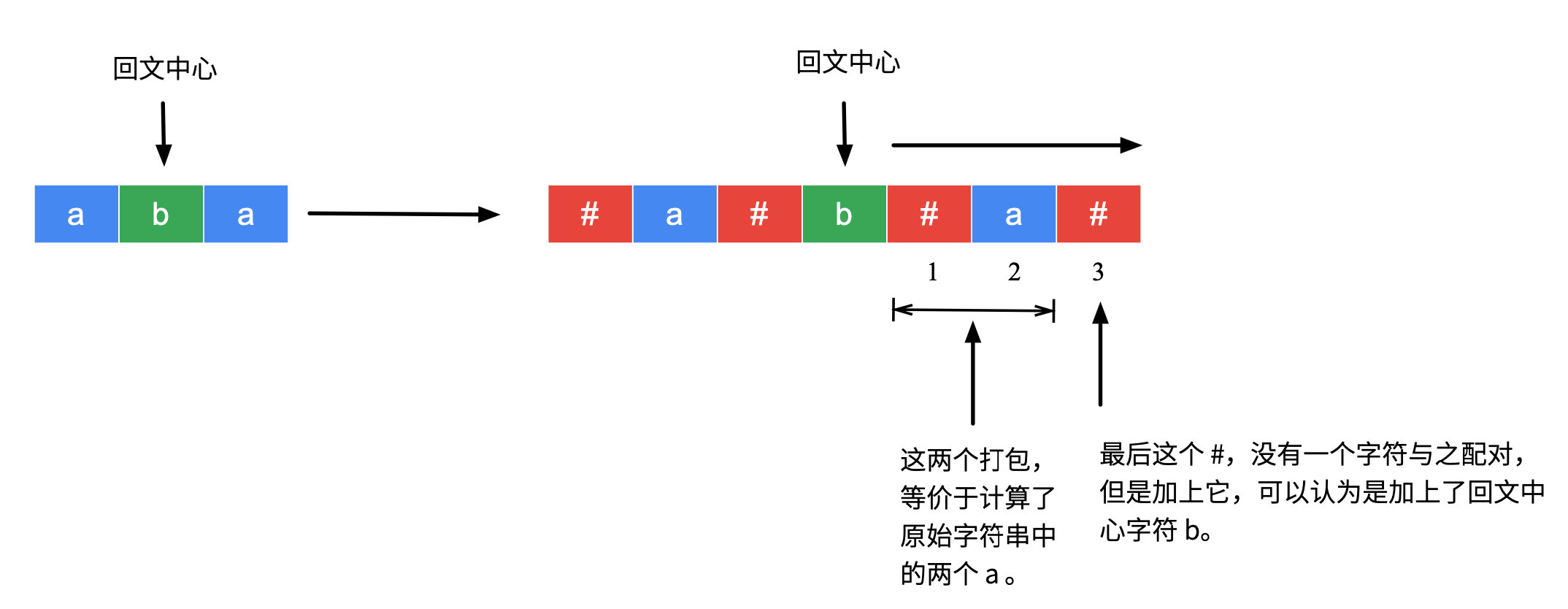
- 如果新回文子串的中心是一个字符,那么原始回文子串的中心也是一个字符,在新回文子串中,向两边扩散的特点是:“先分隔符,后字符”,同样扩散的步数因为有分隔符
#的作用,在新字符串中每扩散两步,虽然实际上只扫到一个有效字符,但是相当于在原始字符串中相当于计算了两个字符。因为最后一定以分隔符结尾,还要计算一个,正好这个就可以把原始回文子串的中心算进去;
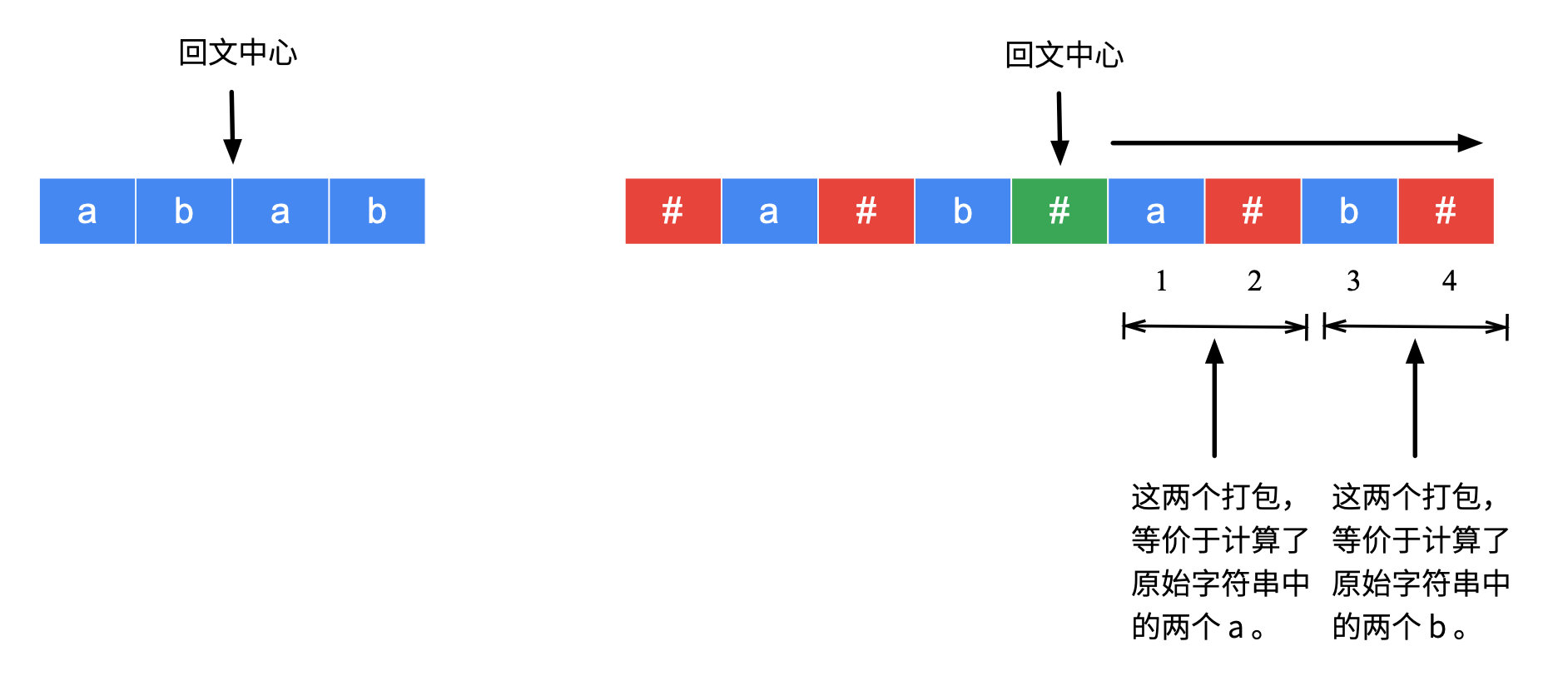
- 如果新回文子串的中心是
#,那么原始回文子串的中心就是一个“空隙”。在新回文子串中,向两边扩散的特点是:“先字符,后分隔符”,扩散的步数因为有分隔符#的作用,在新字符串中每扩散两步,虽然实际上只扫到一个有效字符,但是相当于在原始字符串中相当于计算了两个字符。
因此,“辅助数组 p 的最大值就是“最长回文子串”的长度”这个结论是成立的,可以看下面的图理解上面说的 2 点。
到这一步的时候,其实和上面方法二-中心扩散法差不多,没有什么区别。时间复杂度依然为 O(n2)。
于是乎高潮部分来了,也是我花费了很长时间才理解的。
科学家的工作:充分利用新字符串的回文性质,计算辅助数组 p
上面的代码不太智能的地方是,对新字符串每一个位置进行中心扩散,会导致原始字符串的每一个字符被访问多次,一个比较极端的情况就是:#a#a#a#a#a#a#a#a#。事实上,计算机科学家 Manacher 就改进了这种算法,使得在填写新的辅助数组 p 的值的时候,能够参考已经填写过的辅助数组 p 的值,使得新字符串每个字符只访问了一次,整体时间复杂度由O(n2) 改进到 O(n)
具体做法是:在遍历的过程中,除了循环变量 i 以外,我们还需要记录两个变量,它们是 maxRight 和 center ,它们分别的含义如下:
maxRight:记录当前向右扩展的最远边界,即从开始到现在使用“中心扩散法”能得到的回文子串,它能延伸到的最右端的位置 。对于maxRight我们说明 3 点:
- “向右最远”是在计算辅助数组
p的过程中,向右边扩散能走的索引最大的位置,注意:得到一个maxRight所对应的回文子串,并不一定是当前得到的“最长回文子串”,很可能的一种情况是,某个回文子串可能比较短,但是它正好在整个字符串比较靠后的位置; maxRight的下一个位置可能是被程序看到的(ps: 可能被访问到),停止的原因有 2 点:(1)左边界不能扩散,导致右边界受限制也不能扩散,maxRight的下一个位置看不到;(2)正是因为看到了maxRight的下一个位置,导致maxRight不能继续扩散。- 为什么
maxRight很重要?因为扫描是从左向右进行的,maxRight能够提供的信息最多,它是一个重要的分类讨论的标准,因此我们需要一个变量记录它。
center:center是与maxRight相关的一个变量,它是上述maxRight的回文中心的索引值。对于center的说明如下:
center的形式化定义:
说明:x + p[x] 的最大值就是我们定义的 maxRight,i 是循环变量,0<= x< i 表示是在 i 之前的所有索引里得到的最大值 maxRight,它对应的回文中心索引就是上述式子。
maxRight与center是一一对应的关系,即一个center的值唯一对应了一个maxRight的值;因此maxRight与center必须要同时更新。
下面的讨论就根据循环变量 i 与 maxRight 的关系展开讨论:
情况 1:当 i >= maxRight 的时候,这就是一开始,以及刚刚把一个回文子串扫描完的情况,此时只能够根据“中心扩散法”一个一个扫描,逐渐扩大 maxRight;
情况 2:当 i < maxRight 的时候,根据新字符的回文子串的性质,循环变量关于 center 对称的那个索引(记为 mirror)的 p 值就很重要。
我们先看 mirror 的值是多少,因为 center 是中心,i 和 mirror 关于 center 中心对称,因此 (mirror + i) / 2 = center ,所以 mirror = 2 * center - i。
根据 p[mirror] 的数值从小到大,具体可以分为如下 3 种情况:
情况 2(1):p[mirror] 的数值比较小,不超过 maxRight - i。
说明:maxRight - i 的值,就是从 i 关于 center 的镜像点开始向左走(不包括它自己),到 maxRight 关于 center 的镜像点的步数
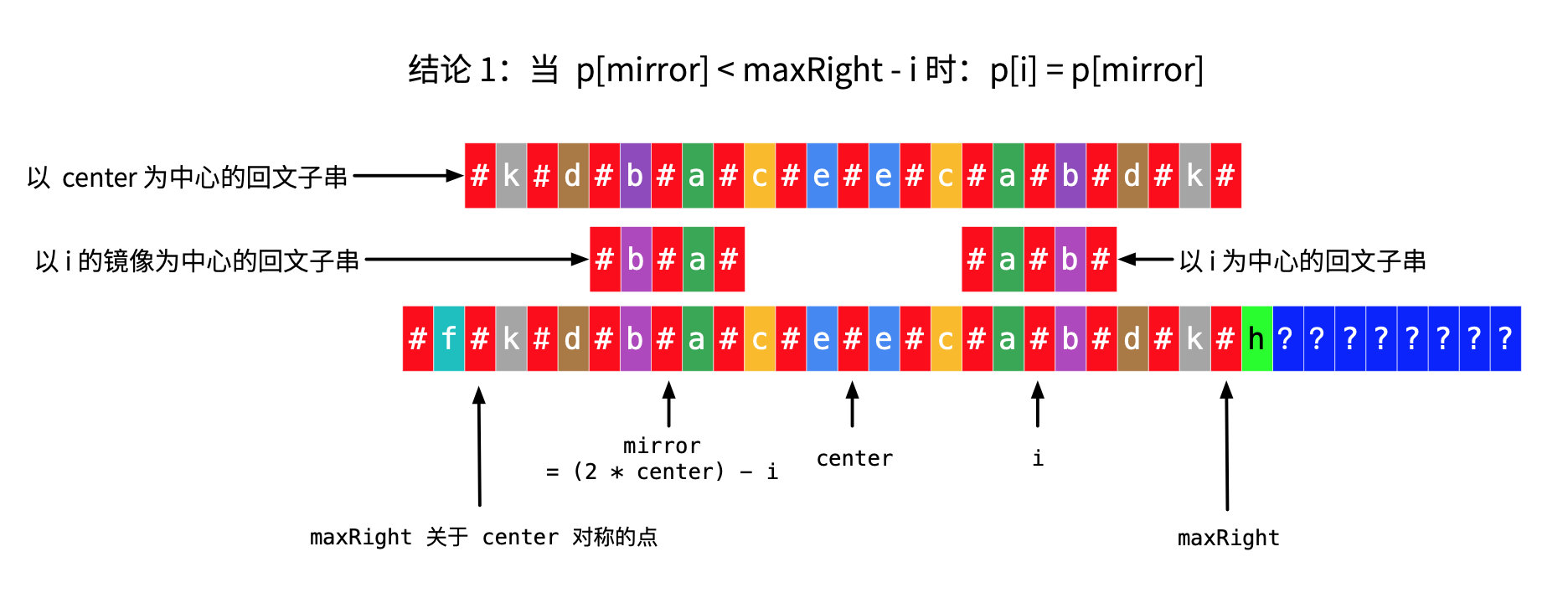
从图上可以看出,由于“以 center 为中心的回文子串”的对称性,导致了“以 i 为中心的回文子串”与“以 center 为中心的回文子串”也具有对称性,“以 i 为中心的回文子串”与“以 center 为中心的回文子串”不能再扩散了,此时,直接把数值抄过来即可,即 p[i] = p[mirror]。
情况 2(2):p[mirror] 的数值恰好等于 maxRight - i。
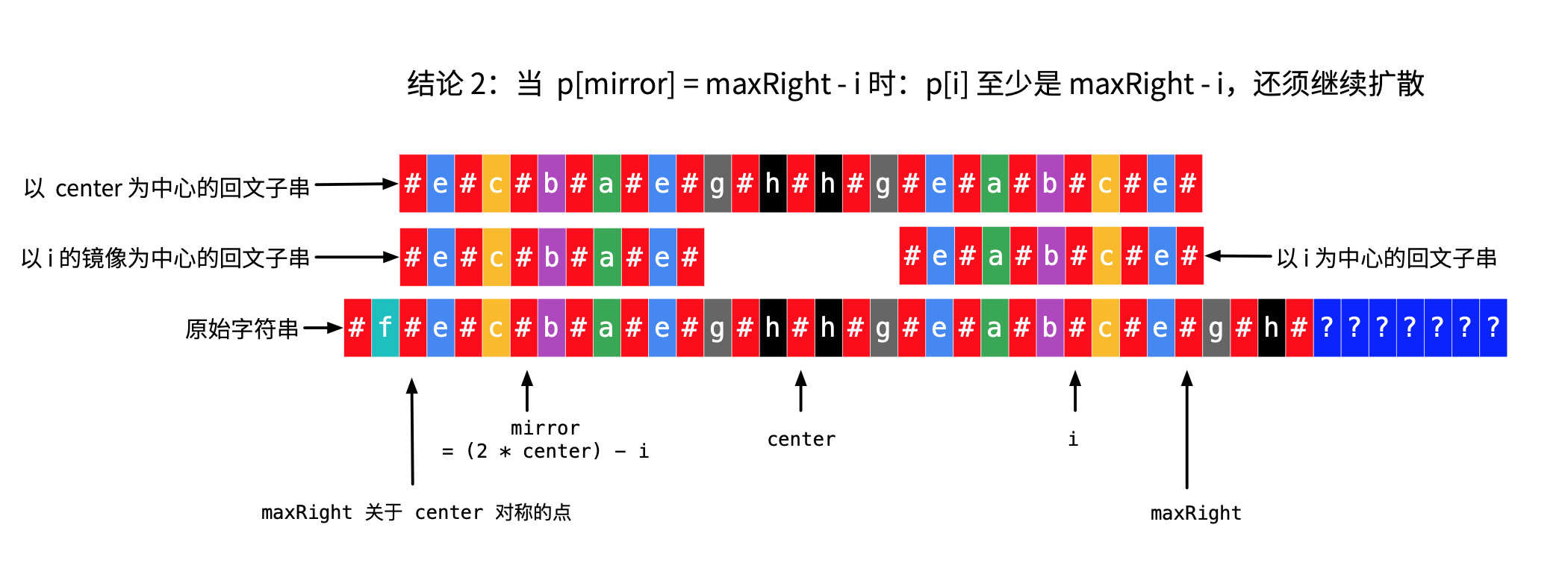
说明:仍然是依据“以 center 为中心的回文子串”的对称性,导致了“以 i 为中心的回文子串”与“以 center 为中心的回文子串”也具有对称性。
- 因为靠左边的
f与靠右边的g的原因,导致“以center为中心的回文子串”不能继续扩散; - 但是“以
i为中心的回文子串” 还可以继续扩散。
因此,可以先把 p[mirror] 的值抄过来,然后继续“中心扩散法”,继续增加 maxRight。
情况 2(3):p[mirror] 的数值大于 maxRight - i。
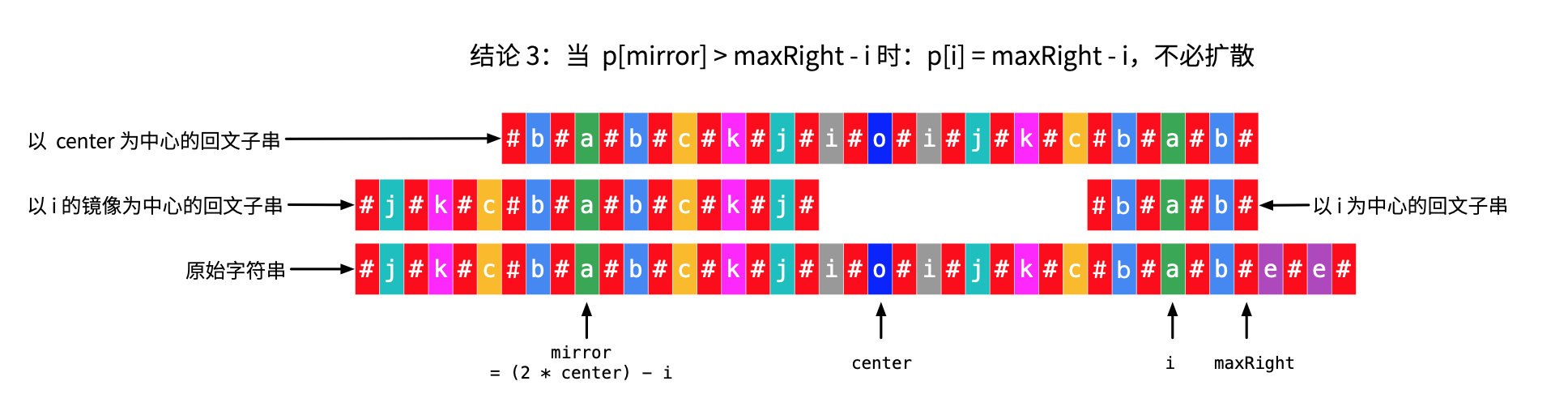
说明:仍然是依据“以 center 为中心的回文子串”的对称性,导致了“以 i 为中心的回文子串”与“以 center 为中心的回文子串”也具有对称性。 下面证明,p[i] = maxRight - i ,证明的方法还是利用三个回文子串的对称性。
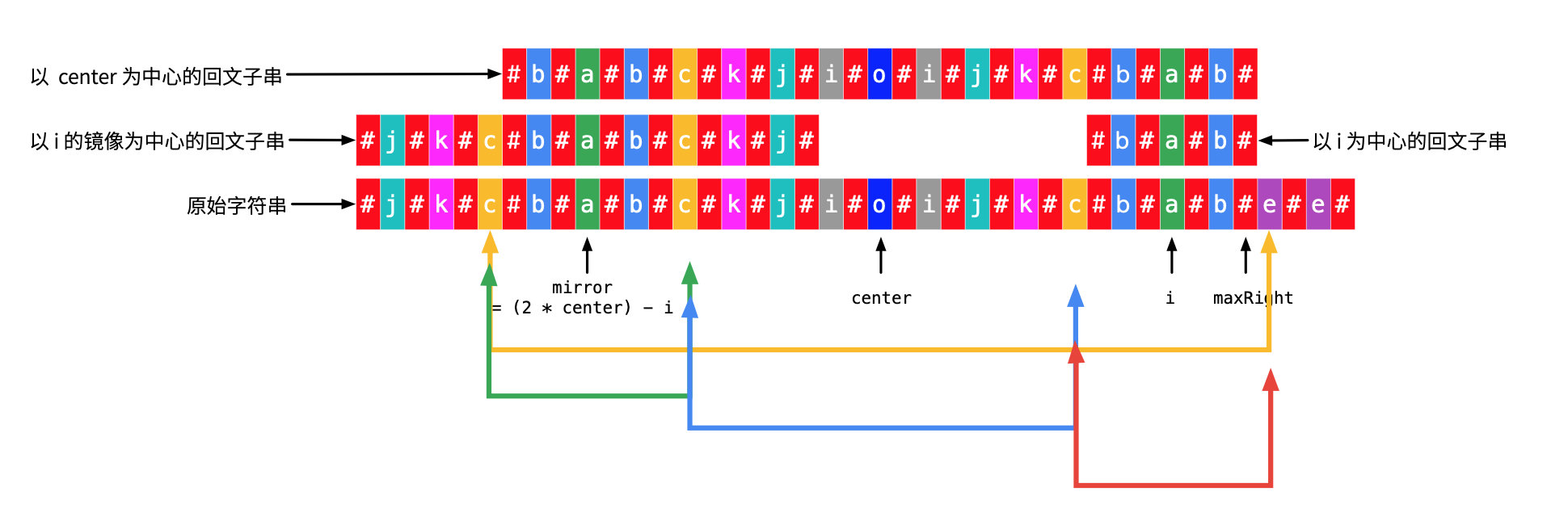
① 由于“以 center 为中心的回文子串”的对称性, 黄色箭头对应的字符 c 和 e 一定不相等;
② 由于“以 mirror 为中心的回文子串”的对称性, 绿色箭头对应的字符 c 和 c 一定相等;
③ 又由于“以 center 为中心的回文子串”的对称性, 蓝色箭头对应的字符 c 和 c 一定相等;
推出“以 i 为中心的回文子串”的对称性, 红色箭头对应的字符 c 和 e 一定不相等。
因此,p[i] = maxRight - i,不可能再大。上面是因为我画的图,可能看的朋友会觉得理所当然。事实上,可以使用反证法证明:
如果“以 i 为中心的回文子串” 再向两边扩散的两个字符 c 和 e 相等,就能够推出黄色、绿色、蓝色、红色箭头所指向的 8 个变量的值都相等,此时“以 center 为中心的回文子串” 就可以再同时向左边和右边扩散  格,与
格,与 maxRight 的最大性矛盾。
综合以上 3 种情况,当 i < maxRight 的时候,p[i] 可以参考 p[mirror] 的信息,以 maxRight - i 作为参考标准,p[i] 的值应该是保守的,即二者之中较小的那个值:
p[i] = min(maxRight - i, p[mirror])
最终代码见下:
代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
L = "#".join(L)
L = "#{}#".format(L)
p = [0 for i in L]
maxRight = center = i = 0
max_len = 0
mid = 0
while maxRight < len(L) and i < len(L):
if i < maxRight:
mirror = 2 * maxRight - i
if mirror >= 0 and mirror < len(L) and p[mirror] != maxRight - i:
p[i] = min(p[mirror], maxRight-i)
for step in range(p[i], len(L)):
if i + step < len(L) and i - step >= 0 and L[i+step] == L[i-step]:
if i + step > maxRight:
maxRight = i+step
center = i
p[i] = step
if p[i] >= max_len:
max_len = p[i]
mid = i
else:
break
else:
for step in range(1, len(L)):
if i + step < len(L) and i - step >= 0 and L[i+step] == L[i-step]:
if i + step > maxRight:
maxRight = i+step
center = i
p[i] = step
if p[i] >= max_len:
max_len = p[i]
mid = i
else:
break
i += 1
print(L[mid-max_len:mid+max_len].replace('#', ''))
说明
以上图包括文字说明,解释来自于 https://www.cxyxiaowu.com/2869.html 。
以上图包括文字说明,解释来自于 https://www.cxyxiaowu.com/2869.html 。
以上图包括文字说明,解释来自于 https://www.cxyxiaowu.com/2869.html 。
我只是把 里面的代码用 python 复现了一下。 如有不懂,最好是看原版。
强烈建议大家关注他。